Openshift on Openstack : Resize attached docker volumes for Openshift nodes
Recently I deployed Openshift 3.9 on Openstack 10z and had ansible variable for docker volume set to 15GiB, later onceI started deploying containers ,I quickly ran out of space in docker volume and couldn’t access openshift console etc .
set openshift_openstack_docker_volume_size: “15”.
set openshift_openstack_docker_volume_size: “15”.
Little intro to Docker Volume in Openshift nodes
set openshift_openstack_docker_volume_size: “15”.
The master and node instances contain a volume to store
docker images. The purpose of the volume is to ensure that a large image or container does not compromise node performance or abilities of the existing node.
The docker volume is created by the OpenShift Ansible installer via the variable
openshift_openstack_docker_volume_size.
Like in my case I needed to resize the docker volume without tearing down and redeploying Openshift.
The following process to resize a volume can be applied to any volume resize situation. I am just stating my scenario and experience in Openshift deployment.
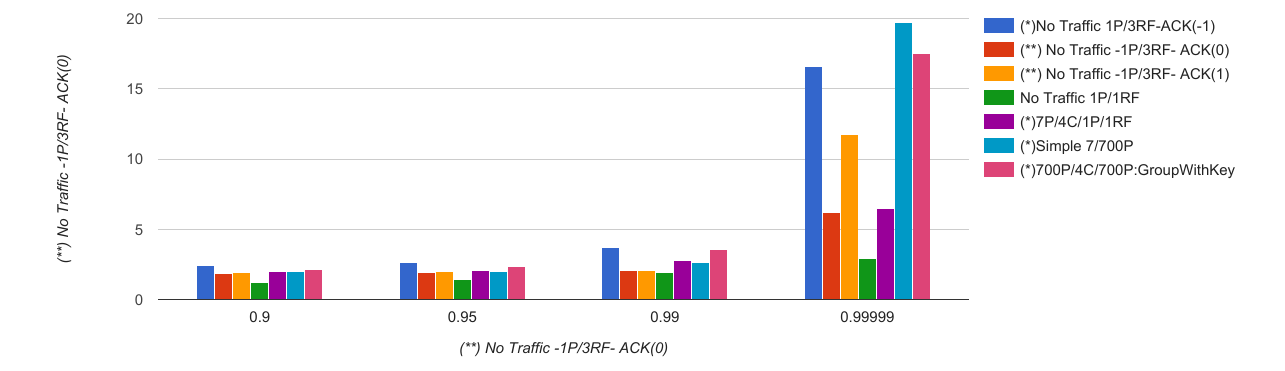
Here you can see the highlighted volume is attached to a master node and it is set to 15GiB.
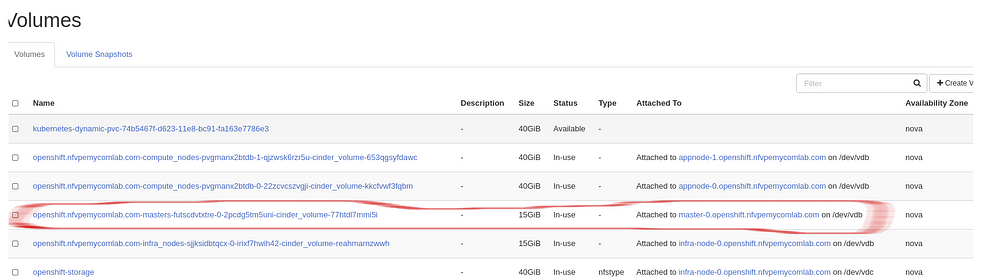
With df -h command on master node we see that volume is full and Openshit performance will be degraded due to lack of space to run containers on this volume.(Example , Openshift console may not respond).
df -h
... /dev/mapper/docker — vol-dockerlv is created with 15Gib

Running Volume list will show , cinder volume in use and attached to master node with 15Gb

Now I need to increase the volume size to 40Gib. Now this can be done two ways. At this time I am not sure which one is safer to do.
- By creating new partition and extending the volume group to include the new logical volume from the new partition.
- Or b y deleting the existing partition and recreating the new partition (hoping it starts from same sector block) with new size of 40GiB
Step one, First we need to resize the volume in cinder.
open stack volume list and Openstack server list to identify volume id and server id that is attached to
volume id: 3f382414-b6ed-4499–8b06-a3fa6794c532
server id :68e9c4ba-1ad7–44f8-bb76–053ba1efa5fa
Stop the server and remove the volume list
openstack server stop 68e9c4ba-1ad7–44f8-bb76–053ba1efa5fa
openstack server remove volume 68e9c4ba-1ad7–44f8-bb76–053ba1efa5fa 3f382414-b6ed-4499–8b06-a3fa6794c532
Resize the volume
openstack volume set 3f382414-b6ed-4499–8b06-a3fa6794c532 — size 40
Re-attach the volume and restart the server
openstack server add volume 68e9c4ba-1ad7–44f8-bb76–053ba1efa5fa 3f382414-b6ed-4499–8b06-a3fa6794c532
openstack server start 68e9c4ba-1ad7–44f8-bb76–053ba1efa5fa
Now when you run volume list you should see 40GiB, and also running fdisk -l shows the available disk is 40GiB. We have successfully grown the volume to desired size, But Wait! we have not grown the Physical volume, logical volume and filesystem.
fdisk -l Disk /dev/vdb: 42.9 GB, 42949672960 bytes, 83886080 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x00094295
Step two, Logical Volume extending
Lets run PVS(Physical volume) vgs(volume group) and lvs(logical volme) command .
previously running df -h , we have seen there are no space in our virtual disk.
Running pvs command shows us there is 0 free space in physical volume
sudo pvs
PV | VG |Fmt |Attr |PSize |PFree /dev/vdb1| docker-vol |lvm2 | a |- | <15.00g 0
Running vgs also shows there is no free space available in volume group
sudo vgs VG #PV #LV #SN Attr VSize VFree docker-vol 1 1 0 wz — n- <15.00g 0
Running lvs shows there is one logical volume which is again full.
sudo lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert dockerlv docker-vol -wi-ao — — <15.00g
So in order to extend this we need to add a physical volume and then extend the volume group .By doing this we get enough space to extend the logical volume and regrow the filesystem.
First step, add physical volume (if you want to modify existing physical volume then you delete the partition and recreate new pv with new size and you will skip the vgextened (volume extend step)
Step three, Add Physical Volume
In my case I have docker volume mapped to /dev/vdb1 .
running fdisk -l shows me that /dev/vdb is now 40Gib, since we ran volume resize
Disk /dev/vdb: 42.9 GB, 42949672960 bytes, 83886080 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x00094295
So I know I have resized the volume to 40GiB and I have extra space available in /dev/vbd
Lets create partition /dev/vbd2
sudo fdisk /dev/vdb Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command.
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): p
Partition number (2–4, default 2): 2
First sector (31457280–83886079, default 31457280):
Using default value 31457280
Last sector, +sectors or +size{K,M,G} (31457280–83886079, default 83886079):
Using default value 83886079
Partition 2 of type Linux and of size 25 GiB is set
Command (m for help): t Partition number (1,2, default 2): 2 Hex code (type L to list all codes): 8e Changed type of partition ‘Linux’ to ‘Linux LVM’ Command (m for help): w The partition table has been altered!
Now running fdisk , displays dev/vdb1 and /dev/vbd2
sudo fdisk -l
……
.….
Device Boot Start End Blocks Id System /dev/vdb1 2048 31457279 15727616 8e Linux LVM /dev/vdb2 31457280 83886079 26214400 8e Linux LVM
We successfully created partition. But the partition won’t be available until next boot,Kernel is still reading from old table… partprobe to rescue.
Run partprobe to inform the OS of partition table changes without reboot.
sudo partprobe -s
/dev/vda: msdos partitions 1 /dev/vdb: msdos partitions 1 2
Now partition is available for us to create the physical volume.
sudo pvcreate /dev/vdb2 Physical volume “/dev/vdb2” successfully created.
Running pvs command shows the new physical volume without any volume group associated with it
sudo pvs PV VG Fmt Attr PSize PFree /dev/vdb1 docker-vol lvm2 a — <15.00g 0 /dev/vdb2 lvm2 — — 25.00g 25.00g
Step four, Extending the Volume Group by adding the new created physical volume (pv)
vgextend — Add physical volumes to a volume group
vgextend docker-vol /dev/vdb2
Checking volume groups with vgs command. We can clearly see we have two pv’s under group docker -vol
sudo vgs VG #PV #LV #SN Attr VSize VFree docker-vol 2 1 0 wz — n- 39.99g 0
But running df -h still shows 15GiB.
/dev/mapper/docker — vol-dockerlv 15G 1.9G 14G 13% /var/lib/docker
df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 30G 13G 18G 43% / devtmpfs 7.8G 0 7.8G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 1.4M 7.8G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup/dev/mapper/docker — vol-dockerlv 15G 1.9G 14G 13% /var/lib/docker tmpfs 1.6G 0 1.6G 0% /run/user/1000
Step five, resize logical volume
Because we still have to resize logical volume by running lvresize to grow 100%
sudo lvresize -l +100%FREE /dev/mapper/docker — vol-dockerlv'
Size of logical volume docker-vol/dockerlv changed from <15.00 GiB (3839 extents) to 39.99 GiB (10238 extents). Logical volume docker-vol/dockerlv successfully resized.
Step six, grow the file system
After resizing logical volume , now we need to grow the file-system, using either xfs_growxfs or resize2fs , depending on your underlying filesystem.
sudo xfs_growfs /dev/mapper/docker — vol-dockerlv
meta-data=/dev/mapper/docker--vol-dockerlv isize=512 agcount=4, agsize=982784 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=3931136, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 3931136 to 10483712
Now running df-h, you should see the docuker volume is fully grown to 40GiB
df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 30G 13G 18G 43% / devtmpfs 7.8G 0 7.8G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 1.4M 7.8G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup/dev/mapper/docker — vol-dockerlv 40G 1.9G 39G 5% /var/lib/docker tmpfs 1.6G 0 1.6G 0% /run/user/1000
That’s all folks!



")
")
")
")
")
")


")